

I know you have heard that Computers only understand zeros and ones and that’s right. Now, can you imagine turning on your computer and seeing a message like this one: 0010100001111110010101.
And somehow be able to understand that it means: “welcome, please enter your password”. It’s bizarre right? Now imagine if your password had to be zeros and ones and you had to type that every-time you power on your computer. I guess you wouldn’t enjoy using computers that much and actually they would probably not be as popular as they are today. But the truth is that this would be our reality if someone hadn’t invented characters encoding.
Characters encodings allow computers to process and display human readable text. But how can computers do that if they only understand zeros and ones? This is when it gets funny. A characters encoding is actually a table that maps sequences of zeros and ones to human readable characters.
Let me give you a simple example:
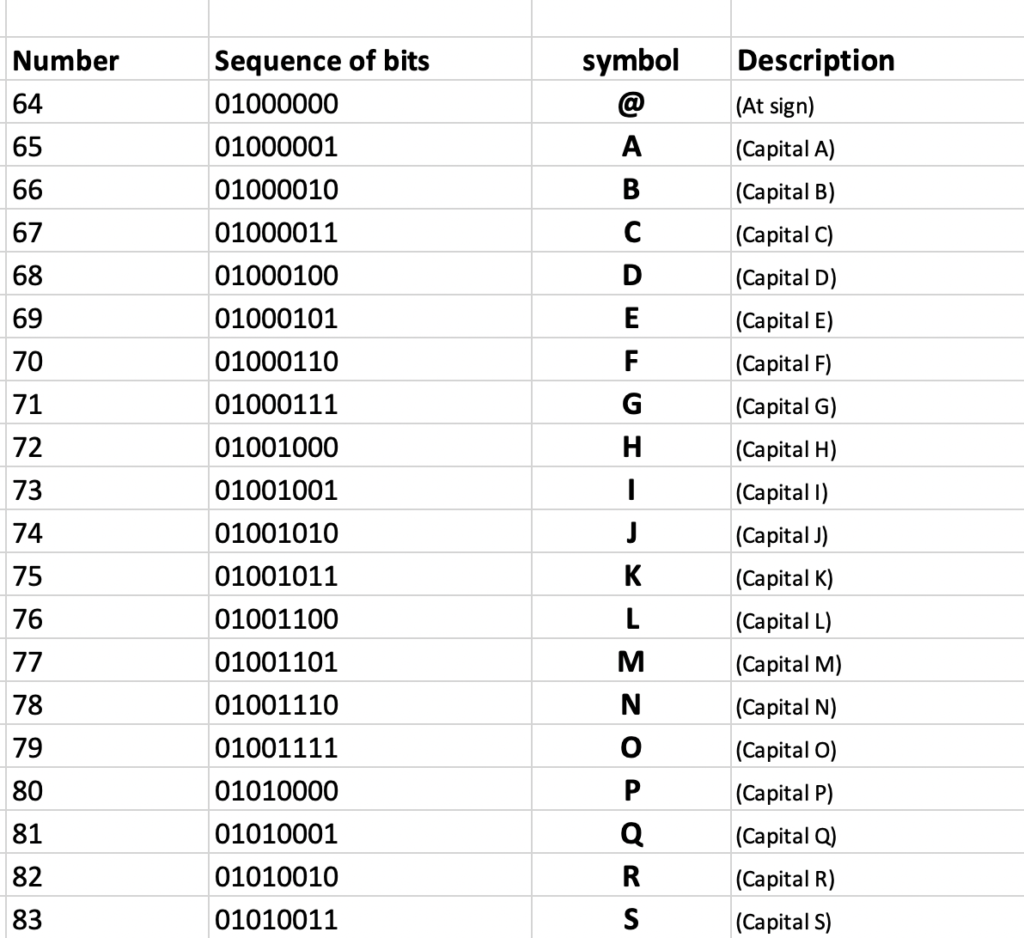
The table I have just shown you is an extract of the ASCII encoding table. It’s a very simple encoding that supports basic US-English characters.
There no characters with accents in that table, but the ASCII extended table already includes characters with accents, from latin and special characters as well.
Because a characters encoding defines the mapping between characters and sequences of zeros and ones, it inherently defines the amount of memory needed to store text written using the encoding. But how so?
Let’s take ASCII as an example. This encoding defines that every supported character is mapped to a sequence of 8 bits, where a bit is a digit that is either zero or one. A bit is the smallest piece of data a computer can handle.
With that in mind, we can affirm that the text “My name is Mario Junior” which has 23 characters, would require a total of 184 bits, which comes from 23 x 8.
Because 8 bits equals 1 byte, we can then say that our text requires 23 bytes of storage.
We can even go a step further and calculate the number of kilobytes, which we can by simply dividing 23 per 1024, since 1 kilobyte is equivalent to 1024 bytes. Then, 23 / 1024 = 0.02 KB.
You can now easily understand what defines the size of a text file. If we were using UTF-8 encoding, interestingly, our text file would have the same size. But if we were using UTF-32, our text would require much more storage, because each of those characters would be mapped to a sequence 32 bits. Which means the size would be = 23 X 32 bits = 736 bits = 92 bytes = 0.08 KB. The size increased by at least 300%. You don’t need UTF-32, believe-me. Most people would be just fine with UTF-8.
Talking about UTF-8, whats so special about it?
See, UTF-8 is an extremely huge table, where each character is mapped to either 8 or 16 or 24 or 32 bits. This is what makes UTF-8 the best encoding for most of the people, because the table is huge enough to support a vast range of characters and most importantly, because it is a variable length encoding. Because of this last characteristic, simple and popular characters are mapped to short sequence of bits and rare and less popular characters are mapped to bigger sequence of bits. The UTF-8 table is so huge that it even contains Chinese characters, but you can easily guess that those are probably mapped to 24 or 32 bits.
Another awesome characteristic of UTF-8 is that it is compatible with ASCII, which means that the same sequence of bits used to represent the character ‘A’ in the ASCII table, is used in the UTF-8 table.
You can’t deny it. Thats really awesome. But as a user you probably came across an image like the one below:
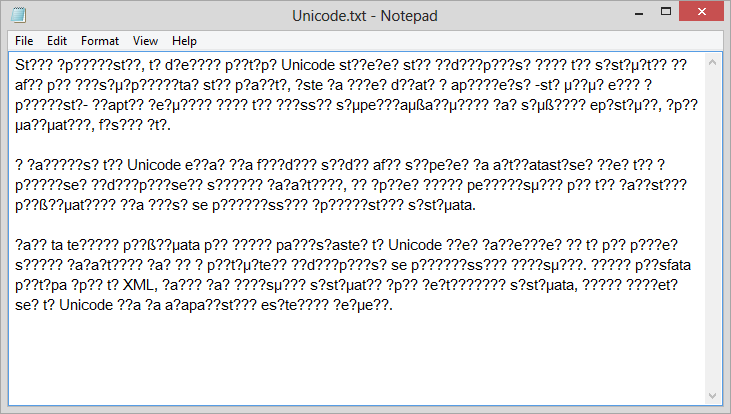
Opening a text file and seeing some weird characters is shocking. But what causes this? This happens when the computer displays characters using an encoding different from the one that was used to write the text, because the characters mapping is different and the tables don’t even support the same characters. It all makes sense. It’s not a virus. You just need to tell the computer the right encoding to use to display the text.
My name is Mario Junior, a guy who writes whenever he is bored enough to do so and this is the best he can do to demystify characters encoding.
It’s always a pleasure.







")

Comentários Recentes